How Ceno Achieves High Performance ZK Proving
Nov 18, 2025 · 5 min read

How Ceno Achieves High Performance ZK Proving
tl;dr Scoll just launched Ceno’s v0.1.0-rc.1 beta release. Ceno is a new high performing Risc-V zkVM capable of poving most Ethereum blocks. It uses a novel chip segmentation architecture for parallelism and GKR for non-uniformity. This results in significantly faster proving, smaller proof sizes, and lower costs, all while connecting into existing OpenVM modular frontend.
Scroll's ZK stack is fundamental to its security and low cost experience. To push these boundaries further, Scroll is developing Ceno, a new ZK proving system. Ceno is a Risc-V zkVM that introduces non-uniformity circuits and novel approaches to parallelism.
Ceno's power isn't a single breakthrough, but a series of fundamental design innovations working as a whole. Let’s explore them.
The Chip Segmentation Architecture
Ceno's architecture divides the proving of long execution traces into dozens (if not hundreds) of smaller shards. Then, in each shard, it puts the proving of one opcode or syscall into one sub-circuit. These sub-circuits communicate with each other via memory. The consistency of memory accesses is protected by offline memory checking.
 Chip segmentation & parallelization exemplified.
Chip segmentation & parallelization exemplified.
To illustrate, take the computation of a + b + c as a single shard, which translates to the following simplified Risc-V code:
# assumes a, b and c are already on memory
lw x01, a # load a into position x01
lw x02, b # load b into position x02
add x03, x01, x02 # temp = a + b
lw x04, c # load c into position x04
add x05, x03, x04 # result = c + temp
# Result is now at position x5
What Ceno does is group these operations by opcode and parallelize their proving. In this case, Ceno creates two groups one for load word lw, used 3 times, and one for additions add, used 2 times:
lw [{x01, a}, {x02, b}, {x04, c}]add [{x03, x01, x02}, {x05, x03, x04}]
The more repeated opcodes, the more Ceno benefits from these optimizations contrary to traditional ZK proving systems where every piece of code has to be processed in a sequential manner.
The pay as you go prover
Ceno is part of the multivariate-based proving family and pioneered GKR usage, a multilinear scheme implemented as its IOP. This enables an per sub-circuit adaptive design that flexibly adjusts its length according to workload, a significant departure from Plonkish systems, which require one circuit to set a fixed size and incur costly padding for short execution trace.
This non-uniformity results in less computational overhead and more efficient proving for varied circuit sizes. The resulting proof can still be verified by a fixed-size smart contract.
Additionally, Ceno implements the GKR tower prover for permutation arguments, which splits arguments into layers and then shrinks intermediate layers using a sumcheck. This process is possible because, unlike traditional Plonkish systems that must commit to every witness, GKR runs several rounds of sumcheck protocol iterations to reduce output layer to input layer. This directly contributes to a smaller final proof size and lower costs. The entire system is designed to use as much GPU as possible from start to finish, minimizing transfers between the GPU and CPU. This GPU acceleration is currently optimized for the BabyBear prime field in a dedicated kernel designed for Ceno.
Can a zkVM be as performant as a custom circuit?
While general purpose zkVMs offer reusability, the ZK space still has the perception that custom circuits are faster. Ceno's current implementation, Ceno Basic, already challenges this with chip segmentation and dynamic GKR circuits. The upcoming Ceno Pro addition is designed to close this gap entirely with further optimizations.
Ceno Pro will adopt a compiler inspired approach, identifying basic blocks (straight-line opcode sequences without jumps) and proving them as highly optimized circuits. The most important innovation is moving stack operations out of the circuit: the verifier simulates them locally just once per block. This reduces prover overhead and constraints in a considerable degree.
This future process is also hybrid. The prover will be able to selectively apply Ceno Basic or Ceno Pro to different program segments, choosing the optimal strategy for the execution trace.
Ceno & OpenVM
Ceno and OpenVM are distinct but complementary components of Scroll's ZK stack. Ceno functions as the new base layer prover, while OpenVM provides the eDSL frontend and the recursion layer.
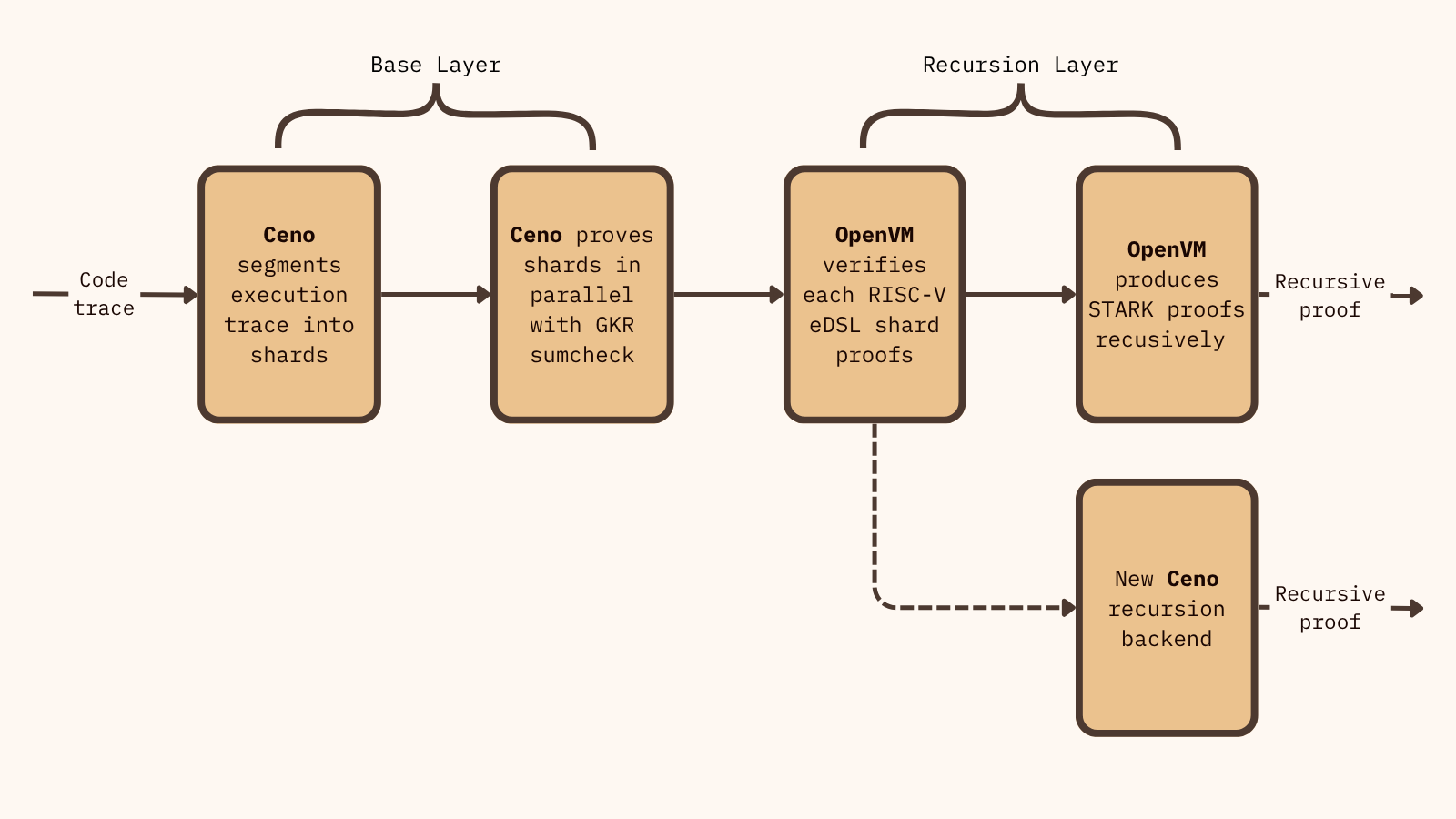 While OpenVM currently handles the recursion layer, Ceno's future backend will plug into the existing OpenVM eDSL.
While OpenVM currently handles the recursion layer, Ceno's future backend will plug into the existing OpenVM eDSL.
Ceno integrates directly at the base layer, serving as a high-performance proof generation engine that tackles the most latency-critical part of the proving pipeline. In the recursive layer, OpenVM takes over aggregating and compressing these proofs into succinct SNARKs for efficient verification.
The complete flow currently operates as follows:
- Ceno receives the transactions in a block from Scroll’s sequencer.
- Ceno segments the execution trace, proving each in parallel using GKR, then output several shard proofs
- Proofs are passed as input to the OpenVM stack for recursion, it generates many recursive STARK proofs.
- Finally, many STARK proofs are aggregated into a single recursive halo2 SNARK proof that can be verified on Ethereum L1.
This modular design is very important to the stack's evolution. In the future, the Ceno team will also develop a dedicated recursive layer backend that will still utilize OpenVM’s eDSL frontend.
This separation of concerns allows the stack to be upgraded one piece at a time, ensuring a smooth transition to more performant components without rebuilding the entire system.
To learn more about how Ceno works and its future features, please refer to the Ceno paper.