Rollups From First Principles
May 20, 2025 · 24 min read

Rollups From First Principles
Written by Jonas Theis.
We would like to thank Toghrul Maharramov and Luca Donno for their thoughtful reviews and comments on an initial draft of this post, and acknowledge contributions from other Scroll team members Alejandro, Péter, Colin, and Mohammad.
TLDR: The article delves into the fundamentals of rollups, an L2 solution that has emerged to scale existing blockchain networks. It explains the core components, including inbox, sequencers, bridges, provers, and L2 nodes, and the tradeoffs involved in rollup design. By leveraging L1 for consensus and data availability, rollups can ensure security and decentralization while addressing challenges like latency, cost efficiency, and user experience. The article also outlines design choices for rollups, such as transaction data vs. state diffs, decentralization levels, and fast vs. slow path mechanisms, aiming to establish a common conceptual framework and guide future developments.
Introduction
Rollups have emerged as a promising solution to scale L1 blockchains, but a lack of standardized terminology and a high-level understanding of their components and interactions often leads to confusion. This article aims to demystify rollup technology by exploring its core principles, fundamental components, and generalized mechanisms. Through an accessible examination of technical elements such as sequencers, bridges, transaction ordering, and data submission methods, it provides a conceptual framework for evaluating rollup architectures.
Rather than striving for detailed technical precision, this article offers a high-level overview of the components and their interactions. The goal is to establish common ground and foster a shared understanding of rollup design, helping readers grasp the tradeoffs involved and inspiring informed innovation in future rollup development.
What is a rollup?
From a high-level, a rollup looks like this:

- Input: rollup data can be any subset of L1 data. Typically this consists of L2 transaction data or L2 state diff posted to DA or calldata, a subset of L1 state (e.g. message queue), and a subset of the L1 ledger (e.g. L1 block hashes). It defines the order of events within the rollup. However, there can be a deterministic reordering step, i.e. the rollup event order does not have to follow L1 order directly but instead create a derived order.
- Deterministic Function: implemented by the rollup software, it takes the ordered input and applies the following functions:
- Chain Derivation Function (CDF): A function that takes the canonical L1 chain as its input (including batches and L1 state, L1 messages) and yields the canonical L2 chain.
- State derivation Function (STF): A function that takes the canonical L2 chain as its input and yields the resulting L2 state.
- Output: rollup chain and state
To put this abstract concept from above into more concrete context let’s consider the following example.
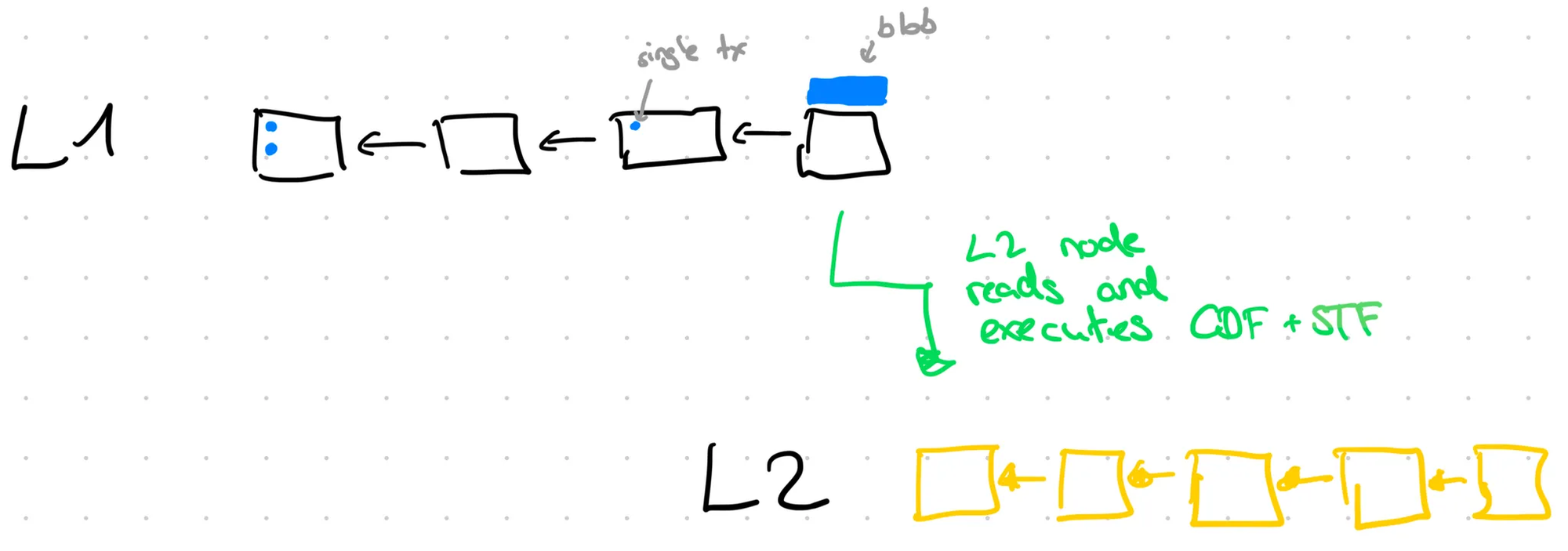
The rollup’s data is posted to L1, usually guarded by some access control. In many rollup designs some entity (aka sequencer) has the rights to pre-order and to append batches of L2 transactions in blobs mainly to amortize cost. Users that don’t want to utilize the sequencer or that are being censored by the sequencer can send L2 messages directly via L1. Ultimately, the ordering of data on L1 is established by L1 consensus, which allows rollups to inherit ordering safety and eventual liveness from their host chain. Full state safety and liveness depend on the rollup’s proving mechanism — e.g., validity proofs (ZK) or fraud proofs (optimistic) — and their respective assumptions.
Anyone can run the rollup software (L2 node) which in turn reads the data from L1 and DA, applies the deterministic function and yields an L2 chain and state. The deterministic function is complete, which means that any invalid input is simply discarded or transformed into something valid and anyone running it over the same input from L1 will get the same result.
However, in practice this process is usually regarded as having too high latency as it will take some time to post to L1 and subsequently read from L1 again. Therefore, an honest sequencer gives pre-confirmations of L2 transactions to users that it will include in a batch of transactions on L1 eventually. This changes the security assumptions dramatically if users act upon a sequencer’s pre-confirmation.
Components and participants
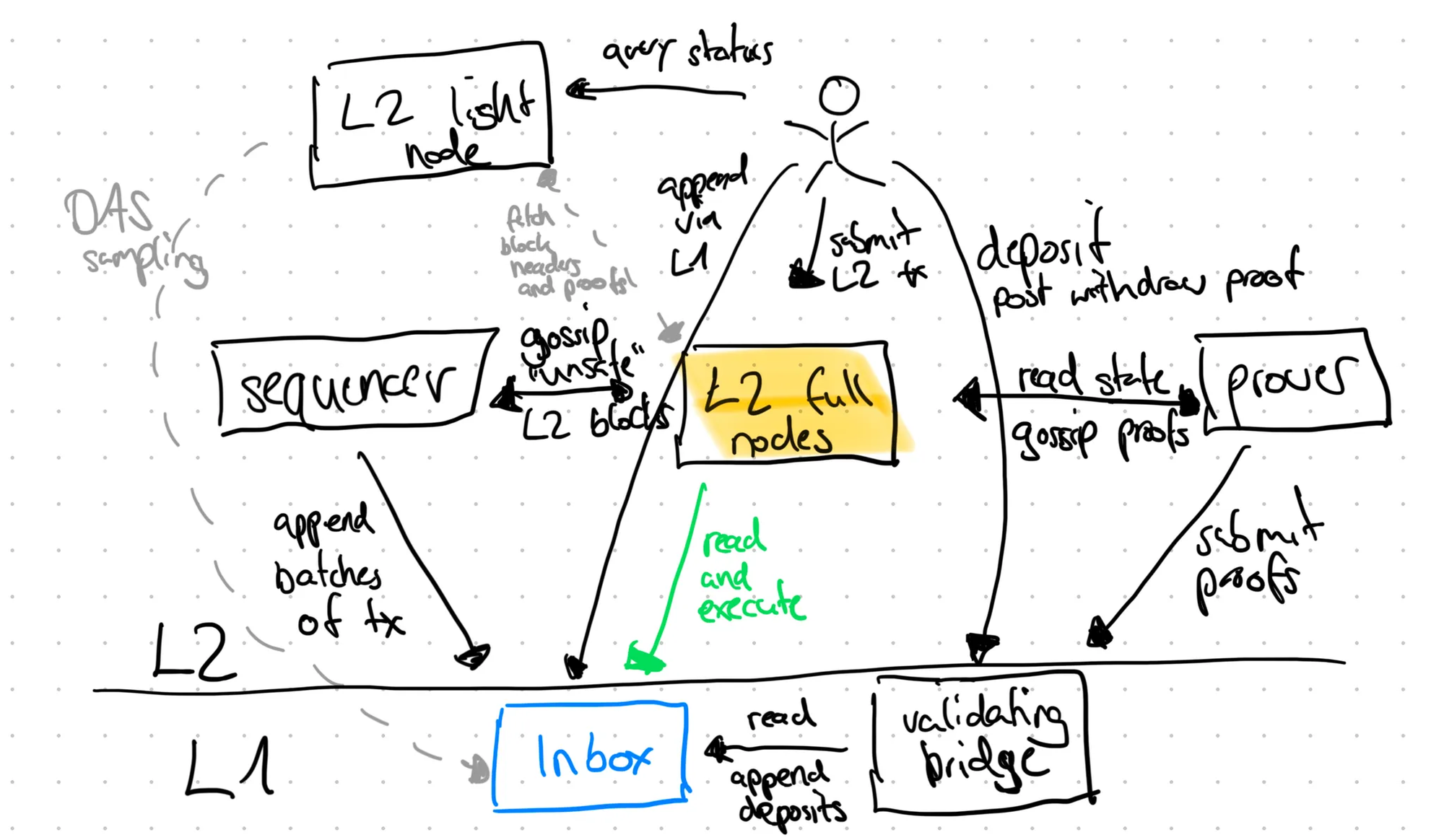
Inbox
The inbox represents the ordered input of the rollup, usually consisting of
- individual transactions: L1→L2 messages initiated on L1 by anyone
- blobs or calldata: batches of transactions submitted to L1, often collected via the L2 p2p network and optionally pre-confirmed (i.e. ordered and acknowledged) by a sequencer before being posted.
For the latter process to work seamlessly, there needs to be some form of access control — otherwise, multiple parties might attempt to pre-confirm and submit conflicting or redundant data, leading to inefficiencies and degraded user experience (e.g. see Taiko’s total anarchy sequencing). This is usually mitigated by having a privileged party called the sequencer.
However, pre-confirmation and p2p distribution are not strictly required. Some rollup designs, such as Facet, take a more minimal approach: calldata or blobs are submitted directly to L1 without any off-chain pre-confirmation or L2 p2p network. In these models, all nodes derive the L2 state purely from on-chain data, simplifying the architecture while sacrificing some UX benefits like fast confirmations and cheaper cost.
Validating bridge
The main job of a bridge is to represent assets from L1 on L2 with a 1:1 peg. Optimally, this happens in a trust-minimized way, meaning that users’ funds are safe as long as the underlying proof system works as expected. While no system is completely risk-free, trust-minimization ensures that the assumptions required for security are relatively weak — such as at least one honest party or bugs in multiple zkVM implementations — and well-defined.
Until now, we haven’t actually talked about bridging assets to/from the rollup. Sending to the rollup is straightforward: make it an input to the rollup by appending to the inbox. In practice this means sending a transaction on L1 to the rollup’s inbox. On L2 this message can be interpreted and the funds credited to the corresponding L2 account. Now the funds are in custody on L1 and minted on L2. A validating bridge thus consists of L1 and L2 components:
- L1: custody funds, append to rollup inbox
- L2: credit funds to user account
What happens if a user wants to withdraw funds L2→L1? The user needs to instruct the bridge to destroy the minted representation of the funds on L2, and the L1 bridge must be convinced that this actually happened before releasing the funds held in custody on L1. Since executing the full rollup logic on L1 would be too expensive — and would defeat the purpose of a rollup — the bridge instead behaves like a validating light client of the rollup: it does not re-execute L2 transactions itself but verifies them based on succinct proofs or challenge mechanisms.
- L1: verify a proof that the user has destroyed the L2 funds and then allow withdrawal based on that evidence
- L2: provide the mechanism to burn or invalidate the funds in a verifiable way
In practice, the official bridge’s design typically defines how the rollup is labeled. The most common types are:
- optimistic rollup: the bridge accepts state and withdraw roots optimistically, can be challenged with a fraud proof within fraud-proof window
- ZK (validity) rollup: the bridge requires a validity proof alongside state and withdraw roots
Technically, a rollup can have multiple bridges, each reaching finality based on different criteria and proofs. However, this is only viable if the bridges share a common ordering of events — typically by relying on the same inbox — to ensure consistency in state derivation. This would complicate things on L2 as not all assets would be fungible anymore. For example there might exist b1ETH and b2ETH where b1 is bridge1 and b2 is bridge2. This and many more concepts around rollup ≠ bridge are described in detail in this article.
L2 full nodes
L2 full nodes are at the heart of the rollup. An L2 full node is part of the L2 P2P network where user transactions and latest, sequencer signed blocks are gossiped. Simultaneously, it reads, executes and consolidates rollup transactions from L1 to the L2 blocks. An L2 full node has all required data to build its local version of the L2 blockchain and state. The nodes can keep track of multiple views on the chain based on different security requirements, also called confirmation rules. This is also where one of the greatest benefits of a rollup and utilizing L1 for ordering comes into play:
- Latest: This is the latest chain head according to the sequencer. The chain moves at the speed at which the sequencer can produce blocks, so potentially very fast (<1s). However, the security guarantees are provided solely by the L2 protocol/network (e.g. slashable stake as equivocation protection). Currently, for most rollups this means trusting the centralized sequencer.
- Safe (optional): This chain head necessitates that a transaction is read from an L1 submitted batch. It moves slower, at the frequency that the sequencer gathers and submits transactions to L1/DA (~tens of seconds to few minutes) and these submissions can’t be reverted. Now, the security guarantees do not depend on the sequencer anymore but instead on L1 and it’s likelihood to reorg.
- Finalized: This chain head requires that a transaction is part of a batch that is finalized in an L1 block. It moves the slowest (safe + 12min in the case of Ethereum and it being live) but provides the best security as a transaction is now final with the L1’s safety guarantees.
These and additional confirmation rules can be exposed to users so that they can make decisions based on latency and security preferences.
Conceptually, an L2 full node consist of rollup node (RN) and execution node (EN). The RN handles all rollup specific tasks like reading from L1, submitting to L1, executing the CDF, and potentially interops between other rollups. The EN is specialized in executing the STF (oftentimes EVM-equivalent).
Sequencer
The sequencer is a regular L2 full node with two special roles:
- hand out pre-confirmations of user transactions, often in the form of L2 blocks. This pre-confirmation is a promise to the user of their transaction execution and that it will be submitted in the promised order to L1/DA. In case pre-confirmations are L2 blocks it is a stronger promise: execution context (header fields like block number, timestamp) and execution results are part of it as well.
- batch L2 transactions to amortize cost and submit to the inbox. Technically, this step could be done by any user that receives transactions from the sequencer on L2. However, as the inbox usually requires privileged access control, in practice, this is mostly done by the same entity that operates the sequencer on L2.
The sequencer can be either a centralized or decentralized component (e.g. using stake and a consensus mechanism). While this distinction isn’t crucial for our general discussion in this article, the security guarantees of latest blocks tend to be stronger with a decentralized sequencer, as it reduces the risk of censorship, equivocation, and single points of failure.
The security guarantees given by a sequencer(s) in the form of a pre-confirmation are significantly different than L1 depending on sequencer decentralization and stake. While the sequencer can’t fabricate invalid state, it can
- censor transactions at will
- potentially modify L2 system state by inserting arbitrary system transactions (this depends on the specific implementation of L2 full nodes — for example, some implementations allow the sequencer to insert L1 messages or other L1 data without verification of it)
- reorder transactions to extract MEV
- equivocate
- Send pre-confirmations about transactions to users.
- Do not include these transactions in submissions to the inbox, thereby invalidating previously pre-confirmed transactions (i.e. double-spend behavior).
- Send conflicting pre-confirmations to different users, leading each one to believe their transaction will be included. This can result in a multi-spend scenario — potentially exploiting many users simultaneously and only limited by how many clients can be deceived at once.
A malicious sequencer can take advantage of users relying on latest blocks. An offline sequencer might also cause liveness interruptions. However, through mechanisms like force inclusion and permissionless batches, users can fall back to safe or finalized blocks and regain L1 security guarantees. That is, for example by submitting transactions via L1 the sequencer can’t censor (exception is hand-off problem) and users can effectively force include a transaction. For permissionless batches, after a timeout the access control can be lifted so that anyone can act as a sequencer and submit batches of transactions.
Prover
Provers are responsible for producing proofs (or fault challenges) so that the view of the validating bridge on L1 can advance. As described above, a validating bridge (mostly the rollup’s official bridge) is a validating light client on L1 that does not know or execute the rollup’s transactions. Instead, it relies on validity or fault proofs to establish correctness of the execution. Only when a valid proof is provided (or no fault proof) the bridge eventually releases the funds on L1.
In a state diff based rollup provers take on another role. Validity proofs are here effectively used for compression: instead of submitting all transaction data to the inbox on L1, only the result of transaction execution in form of a state diff (compared to the last posted state diff) is submitted to L1.
Provers rely on L2 full nodes to get the necessary data to produce the proofs. Optimally, producing and submitting proofs is permissionless, i.e. anyone can produce and submit proofs and be rewarded accordingly, so that the bridge’s state can always be advanced and users’ funds are not at risk to be locked indefinitely.
L2 light nodes
L2 light nodes can be run by users for example as part of a wallet to reduce trust assumptions on third-party nodes. This way a user does not need to trust the response of some RPC node but instead verifies correctness and data availability themselves without needing the full data. The exact guarantees a user gets depend on the individual implementation of the L2 light node. Today, in practice, many users use the official bridge via L1 as their “validating light client”.
Users
Users directly or indirectly interact with all components of the rollup. The majority of users interact with the rollup through apps and might not even be aware that a blockchain is involved in their interaction with an app.
Users most commonly submit transactions via app interfaces, thus interacting with RPC nodes to submit and check transaction status. User behavior and demand drives congestion and therefore congestion related fees within the blockchain and adds pressure to queried RPC nodes.
Most average users care about a snappy and seamless experience (low latency) and take safety properties for granted. Therefore, making users responsible for understanding nuances of the rollup’s security is unreasonable. Users also expect no or low fees as they are used to from web2 applications.
Properties
Like with L1 blockchains there are many properties a rollup system and design can optimize for. This section introduces some of these properties at a high level.
Security
Safety: Ensures that the system operates correctly and consistently, preventing invalid state transitions or incorrect outcomes.
Liveness: Ensures that the system continues to operate and progress, allowing transactions to be processed and included in the blockchain within a reasonable time.
Safety and liveness differ vastly in the fast path vs. slow path. Fast path means a user interacts with the sequencer on L2 and acts upon sequencer pre-confirmations (i.e. latest blocks). Therefore, effectively relying on the sequencer’s security guarantees. The sequencer might be centralized or decentralized (with stake and consensus) but it usually provides less decentralization and security than L1.
Slow path means a user interacts with the rollup through its L1 mechanisms like force inclusion and permissionless batch and proof submission and waits for finalization on L1 (i.e. safe and finalized blocks). Thereby incurring higher cost and significantly higher latency but increased security. With force inclusion a user sends a transaction via L1 and the transaction will become part of the rollup. There’s nothing the (centralized) sequencer can do about it (e.g. in case it was censoring in the fast path). Permissionless batch submission allows users to submit batches of transactions, thus continuing the rollup process in case the permissioned operators are censoring or offline. Permissionless proof submission allows users to generate proofs to advance the state of the validating bridge. These mechanisms usually involve deep technical knowledge and are expensive. Therefore, they should be seen as a last resort/emergency option only.
Decentralization
A core principle of blockchain technology, decentralization promises a trustless, resilient, credibly neutral and censorship resistant network. The decentralization of a rollup can also roughly be distinguished into slow path vs fast path. L2Beat’s stage 1 and 2 decentralization is only concerned with the slow path, giving worst-case guarantees to users.
However, in practice most users will interact with a rollup in the fast path. Decentralization of the fast path includes topics such as sequencer decentralization, sequencer equivocation prevention, client diversity, network decentralization (e.g. how many L2 full nodes), L2 light clients.
User experience
Most users care about directly user facing problems: cost efficiency, low transaction confirmation latency, low withdrawal latency. Indirect properties such as high throughput, the ability to handle a high volume of transactions while providing low transaction latency and low fees, are invisible to users. Similarly, safety and liveness are invisible to most users in the happy path and are taken for granted which could lead to problems in emergency situations.
Developer experience
Since most rollups are built on Ethereum and the Ethereum ecosystem is still one of the biggest, they provide some form of EVM equivalency or compatibility with Ethereum to make interaction between the L1 easier and provide familiar EVM developer environment and tooling.
Recent trends are also implementing alternative VMs for rollups. This might be other blockchain specific VMs or by allowing general purpose programming languages to be used.
Portability and independence of L1
While a rollup might aim to be functionally equivalent to Ethereum, it may still want to retain operational sovereignty. This creates a spectrum of how tightly coupled the rollup is to its L1 — both in terms of block generation (e.g. based rollups) and overall L1-awareness.
L1-awareness refers to the extent to which a rollup relies on the internal behavior of its L1 — such as block structure, ordering rules, or specific protocol assumptions — to optimize certain properties. This reliance can improve performance or cost efficiency but comes at the expense of portability: if the L1 changes, the rollup may need to upgrade alongside it to stay compatible.
In contrast, a rollup that relies solely on standard EVM functionality is more easily generalized and can be adapted to run on other EVM-compatible L1s with minimal changes.
Tradeoffs when designing a rollup
When designing a rollup protocol, certain properties can have higher priority than others which results in a very big design space. In fact, dozens of rollups with different properties are in production today with many more coming in the next months showcasing the endless possibilities live.
Choosing priorities highly depends on the goals of a rollup design but it is certainly not easy, as properties are oftentimes closely related and tradeoffs between individual properties are necessary. We can distinguish between fundamental and operational tradeoffs:
- fundamental tradeoffs have influence on the design of the rollup in a way that it is not trivial to change said behavior. The tradeoff fundamentally shapes the design of the rollup.
- operational tradeoffs do not impact a rollup’s design but can be activated on demand in any given deployment of the rollup.
Fundamental tradeoffs
Transaction data (TD) or state diffs (SD) as data posted to L1/DA
Posting the rollup’s data to L1/DA can mainly be done in 2 ways: posting the full L2 transaction data or posting a state diff (i.e. the result after execution of L2 transactions together with a validity proof that the execution is correct). The latter point is critical and the reason why SD are only possible with ZK rollups. For optimistic rollups, the full transaction history needs to be available so that an observer can re-execute and produce a fault proof. For ZK rollups, the existence of a state diff is sufficient as the most recent state can be reconstructed and verified from L1/DA data.
Adopting SD as DA mechanism has major implications for a rollup’s design:
- An SD-based rollup conceptually embraces ZK technology twofold: (1) to compress L2 transaction data into a SD, and (2) to prove the correctness of compression and execution. Using ZK for compression can lead to much better DA utilization and compression ratio of L2 transaction data which is the main benefit of using SD.
- Due to the fact that proofs are used for proving the compression and correctness of L2 transactions even for the inbox, the rollup’s components blur into each other and oftentimes a clear distinction between inbox and bridge is not possible anymore. For example, limitations in the bridge’s proof system might limit the possibilities of the STF and thus resulting in the bridge defining the rollup’s capabilities and finality.
- The full history of transactions is not available, there is a lack of transparency. This could also be seen as a privacy feature.
- Pricing transactions becomes more difficult as the data storage price of a transaction depends on its outcome and whether it modifies storage slots that already have been modified in the same state diff. This is similar to pricing transactions with TD when the data is compressed: compression and SD (and the corresponding discount factor) are both global properties that often cannot be directly correlated with individual transactions.
- A force inclusion mechanism becomes more complicated as a user can’t simply append their transaction to the inbox anymore. With SD the inbox is a ordered set of execution results with validity proof as opposed to a simple list of transactions.
- Permissionless batch submission becomes more convoluted due to the fact that a SD can be invalid and therefore users need to provide a SD + proof. This fact usually also leads to a more difficult path to decouple sequencer and provers and therefore hampers decentralization.
- With TD nodes can re-execute (or consolidate) state from L1/DA as soon as it is committed and therefore achieve fast finality. With SD this was thought to be not possible as one usually needs to wait for the proof to verify the correctness of a SD.
- Within this discussion a potential path to fast finality with SD was explored. Though, so far, these discussions and findings are only theoretical.
- Overall, state diffs make further design more involved as data is missing and the rollup’s design always needs to work around it.
L1-unaware (state contained in SC) or L1-aware
Some rollups might choose to utilize intrinsic features of the L1 to save cost, simplify design and smart contracts. For example, by using an EOA as the inbox and using the L1’s transaction ordering mechanism an order of the inbox data can be achieved. This creates dependencies to the L1 network beyond its VM, might necessitate upgrades of the rollup together with the L1 and makes the rollup’s design less portable to a different L1, even if it uses the same VM.
As an example, let’s consider a CDF that is able to read L1 blocks. This CDF can’t be applied to another chain as the L1 blocks and its internals are different. It also means upgrades to L1 will affect the proving: (1) in case L1 blocks change, the proof system might need to be updated to support this, and (2) in case the L1 increases throughput, it might increase the rollup’s cost for proving as it needs to process more transactions when reading L1 blocks.
Fork-choice: based or run-ahead
This article explains the concept of (re)based rollups: a rollup can choose to be either host-following or host-watching. All rollups in existence today are host-following, meaning that the rollup’s history is decided by the L1’s order which implies that a rollup might reorg together with its host chain. Host-watching means that individual events (e.g. a fraud proof) could alter the rollup’s history without a reorg on L1, simply by modifying the order or validity of existing data.
Host-following is a spectrum: on the one end there’s based rollups which work in tandem with the L1 and will reorg as soon as the L1 reorgs. In the center there’s run-ahead rollups, where non-equivocation of the sequencer is assumed and it issues pre-confirmation of which data will be posted to L1. Therefore, the L2 only needs to reorg if data it consumed from L1 is reorged. There might be protocol rules that force the sequencer to be in lockstep with L1 and thus necessitate an L2 reorg if an L1 reorg is sufficiently deep. On the other end of the spectrum is a run-ahead rollup that only consumes finalized data from L1. This way a reorg on L1 can not influence the state of the L2.
Depending on how close and synchronized to L1, i.e. how quickly deposits will be processed, a rollup wants to be this has significant impact on the rollup’s design.
Operational tradeoffs
decentralization
One common tradeoff that rollup operators need to make is about throughput and decentralization. If node requirements are too high, it makes it less accessible for users to run their own nodes which makes the network more centralized. One option to counter this might be an emphasis on L2 light clients but the core of the problem still remains.
Another inherent trade-off for rollups is between decentralization and latency specifically regarding a (decentralized) sequencer. Running consensus (to agree on the transaction order on L2) among nodes always increases the latency at least linearly with the number of nodes (though pipelining can be used).
Some rollup designs, like MegaETH, hyper-optimize for performance and the rollup’s design is highly impacted by this priority. While throughput can be increased by more efficient algorithms and software, there is a fundamental decision to be made about which hardware specifications are required.
finalization time and cost amortization
When aggregating and compressing L2 transactions, naturally a better compression ratio can be achieved the more data is compressed. This is true for TD and SD, albeit more pronounced in SD rollups. However, this means the sequencer would wait longer to submit data to L1 which will delay the time to finalization. This is a direct tradeoff between fast finality and cost amortization that the operator needs to make. This is exacerbated with lower throughput.
For ZK rollups there’s an additional tradeoff for proof submission, where essentially the same problem comes up, especially with low traffic. Verifying a proof onchain is expensive, therefore it is cheaper to amortize cost amongst more and more transactions. This would mean longer finalization time (if only SD is posted) or at least longer withdrawal times of the bridge (for both TD and SD).
Conclusion
The article provides a high-level exploration of the fundamental components, principles, and mechanisms of rollups. By breaking down the individual elements such as inbox, sequencer, bridge, and L2 nodes, it establishes a conceptual framework that helps readers understand the tradeoffs and design decisions involved in rollup systems. It also highlights the dual paths of fast and slow path, illustrating the balance between latency, security, and decentralization.
The overarching goal of this article is to foster a shared understanding and common terminology within the rollup ecosystem. By focusing on foundational principles, it aims to bridge knowledge gaps and facilitate collaborative innovation in the development of next-generation rollups. As rollups continue to evolve and address critical challenges, this framework serves as a starting point for researchers and developers to refine and optimize rollup designs.